

Fact Sheets about Genomics
Polygenic risk scores
Many people have an illness, or several illnesses, that are affected by changes in either one or many of their genes, frequently coupled with environmental factors.
Researchers are studying these changes to understand the role that genetics plays in diseases across different populations.
A “polygenic risk score” is one way by which people can learn about their risk of developing a disease, based on the total number of changes related to the disease.
Featured video
What is a genomic variant?
All humans have near-identical DNA sequences across the estimated 6 billion-letter code for their genome.
Slight differences exist between individuals, making each of us unique. These differences, called genomic variants, occur at specific locations within the DNA.
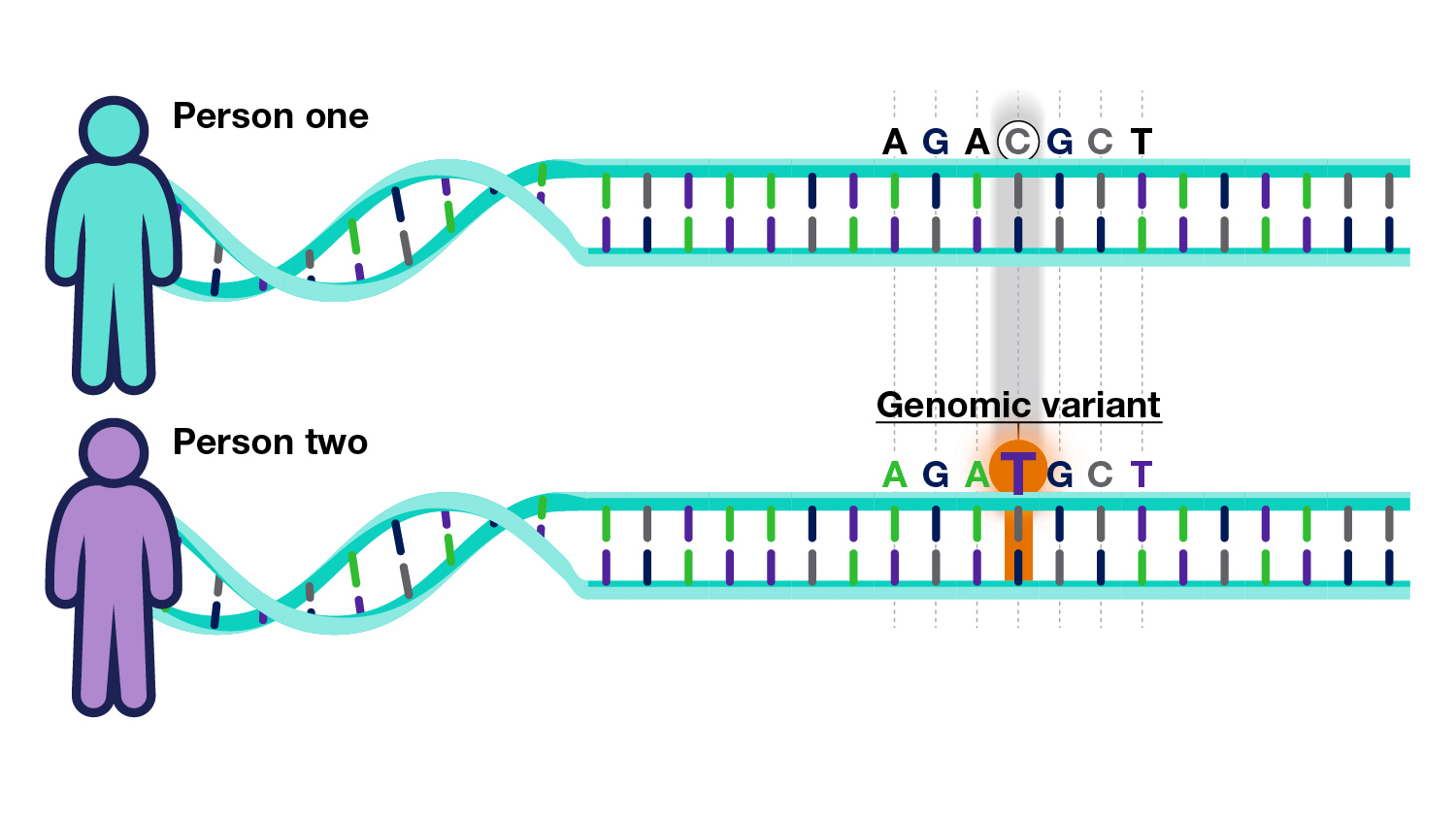
DNA is read like a code. This code is made up of four types of chemical building blocks - adenine, thymine, cytosine and guanine, abbreviated with the letters A, T, C and G. A genomic variant occurs in a location within the DNA where that code differs among people.
For example, in Person One below, the location shows a "C" base. But in the same location in Person Two, it is a "T."
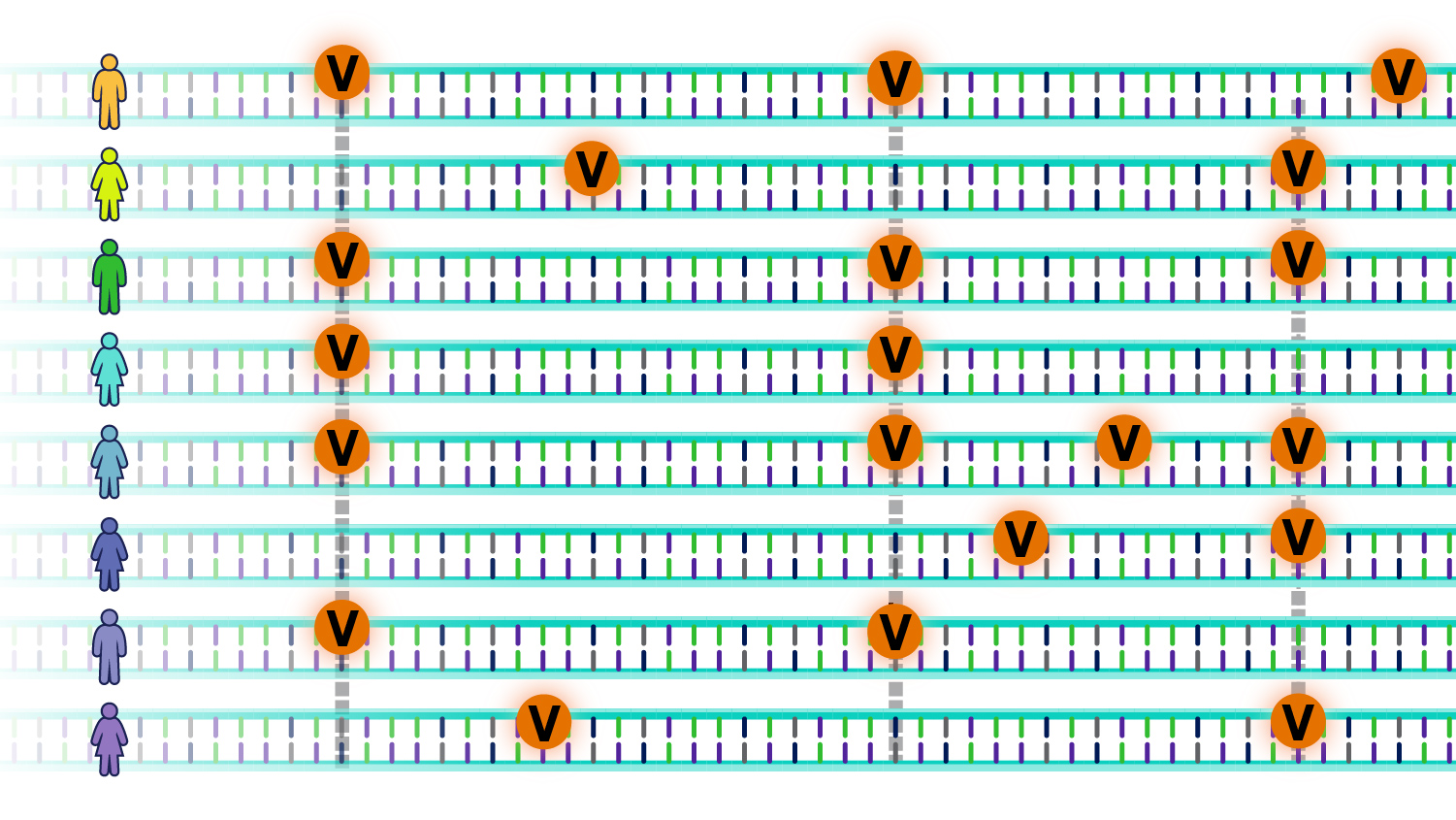
There are roughly 4 to 5 million such genomic variants in an individual’s genome. These variants may be unique to that individual or occur in others as well.
Some variants increase the risk of developing diseases, while others may reduce such risk; others have no effect on disease risk.
The question is: How do these genomic variants influence the risk for specific diseases?
Single-gene vs. complex diseases
Researchers often divide genetic diseases into two classes: those that are associated with a single gene and those that are influenced by multiple genes and environmental factors. Many diseases fall on a spectrum between these two extremes.
Single-gene diseases
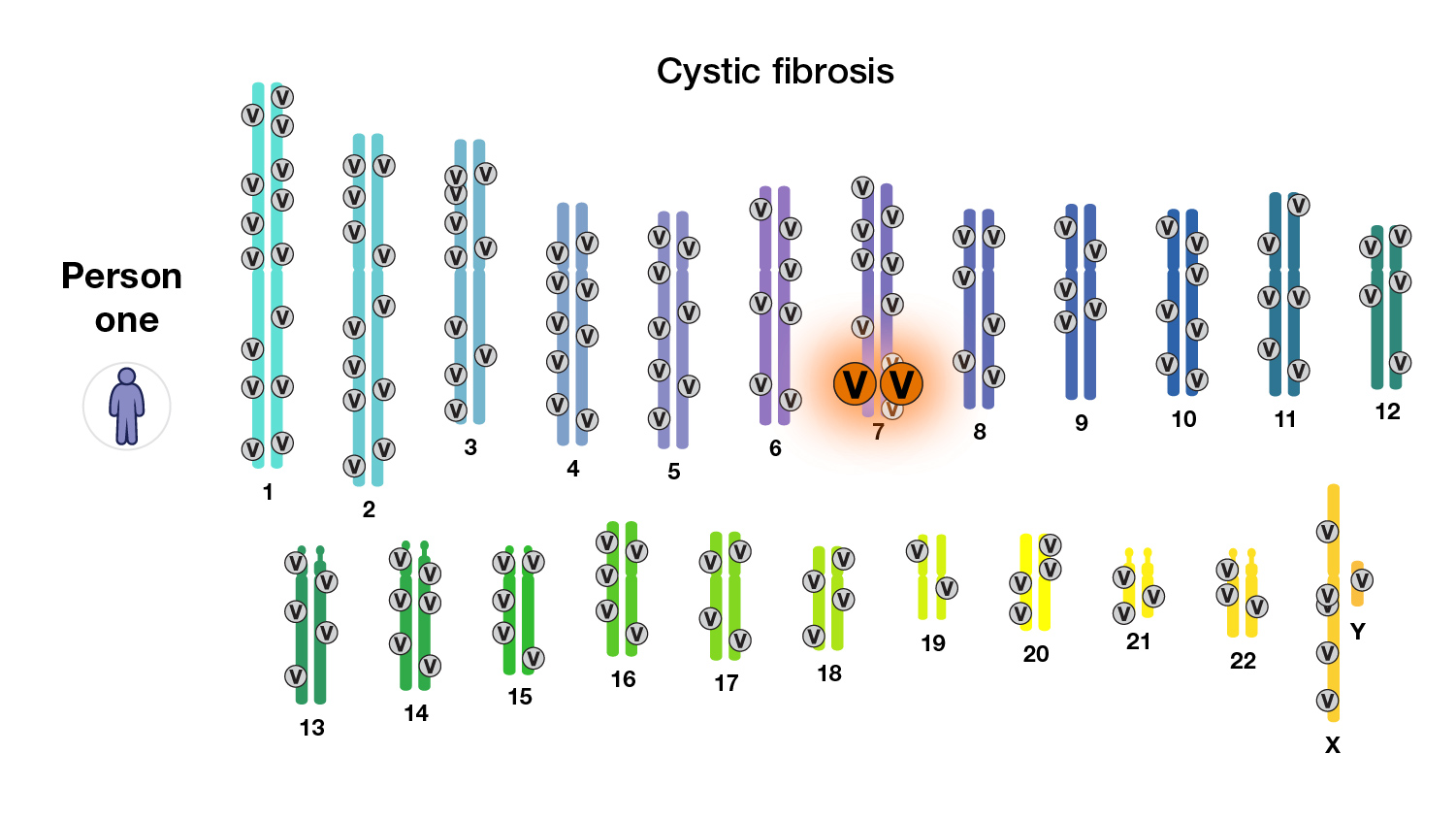
Many inherited diseases can be traced to variants in a single gene. Cystic fibrosis, a progressive genetic disease that causes long-term lung infections and limits the ability to breathe over time, is caused by variants in the cystic fibrosis transmembrane conductance regulator (CFTR) gene on chromosome 7.
Complex diseases
Complex diseases occur as a result of many genomic variants, paired with environmental influences (such a diet, sleep, stress and smoking). They are also called “polygenic” diseases - with “poly” meaning many and “genic” involving genes.
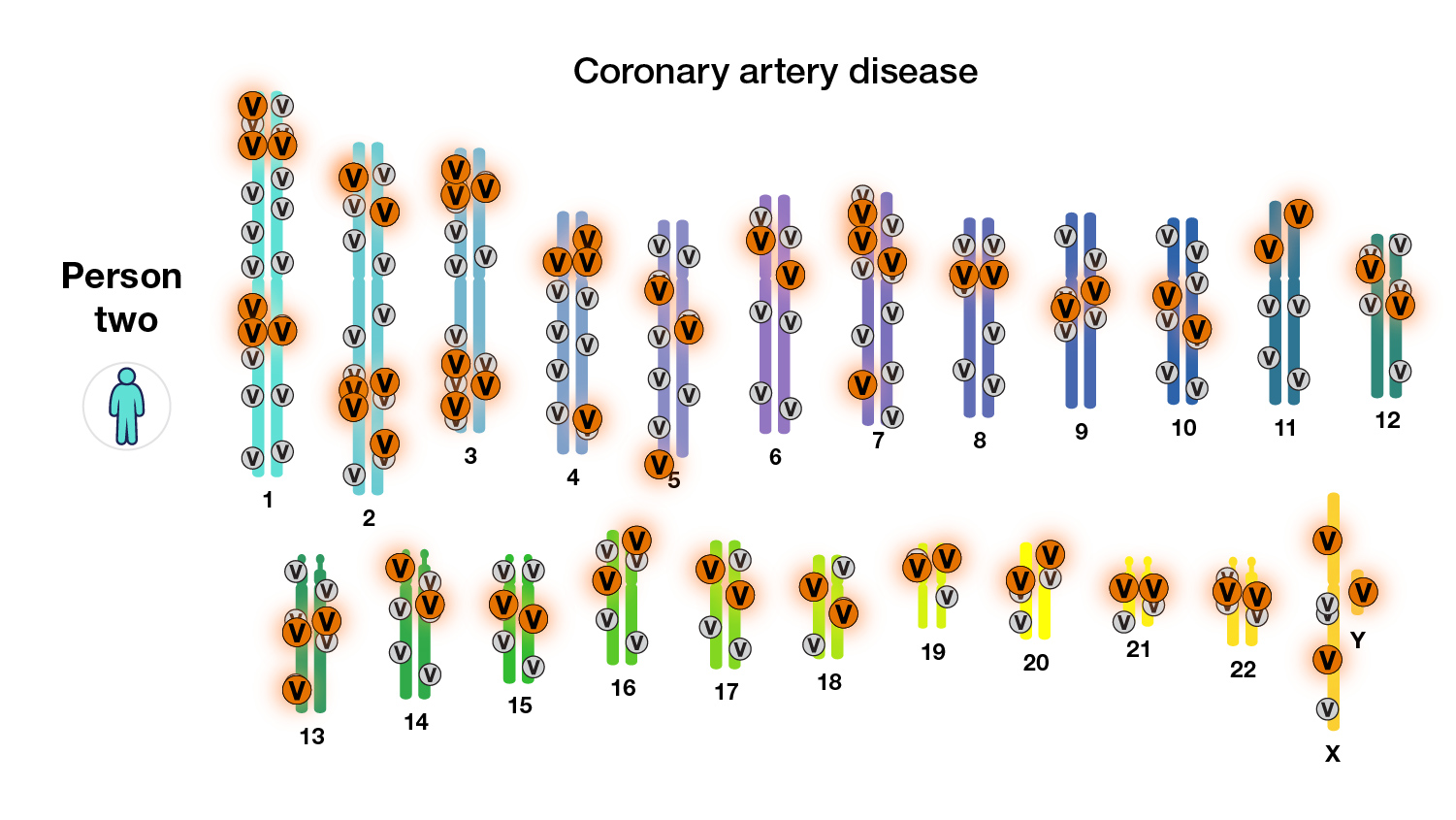
Coronary artery disease is a complex disease. Researchers have found about 60 genomic variants that are present more frequently in people with coronary artery disease. Most of these variants are dispersed across the genome and do not cluster on one specific chromosome.
Calculating polygenic risk score
How to interpret a polygenic risk score
A polygenic risk score can only explain the relative risk for a disease. Why relative? The data used for generating a polygenic risk score comes from large scale genomic studies. These studies find genomic variants by comparing groups with a certain disease to a group without the disease.
A polygenic risk score tells you how a person’s risk compares to others with a different genetic constitution. However, polygenic scores do not provide a baseline or timeframe for the progression of a disease. For example, consider two people with high polygenic risk scores for having coronary heart disease. The first person is 22 years old, while the latter is 98. Although they have the same polygenic risk score, they will have different lifetime risks of the disease. Polygenic risk scores only show correlations, not causations.
Absolute risk is different. Absolute risk shows the likelihood of a disease occurring. Women who carry a BRCA1 mutation have a 60-80% absolute risk of breast cancer. This would be true even without any comparison to any groups of people.

Each polygenic risk score can be put on a bell curve distribution. Most people will find their scores to be in the middle, indicating average risk for developing a disease. Others may find themselves on the tail ends, putting them at either low or high risk. People with scores on the high-risk portion of the spectrum may benefit from discussions about this risk with their physicians and genetic counselors for further health assessments.
Who benefits from a polygenic risk score?
The majority of genomic studies to date have examined individuals of European ancestry. Because of this issue, there may not be adequate data about genomic variants from other populations for calculating a polygenic risk score in those populations. This historic lack of diversity in genomic studies is also a concern for other genomics-related research areas and contributes to a widespread concern about increasing health disparities beyond polygenic risk scores.
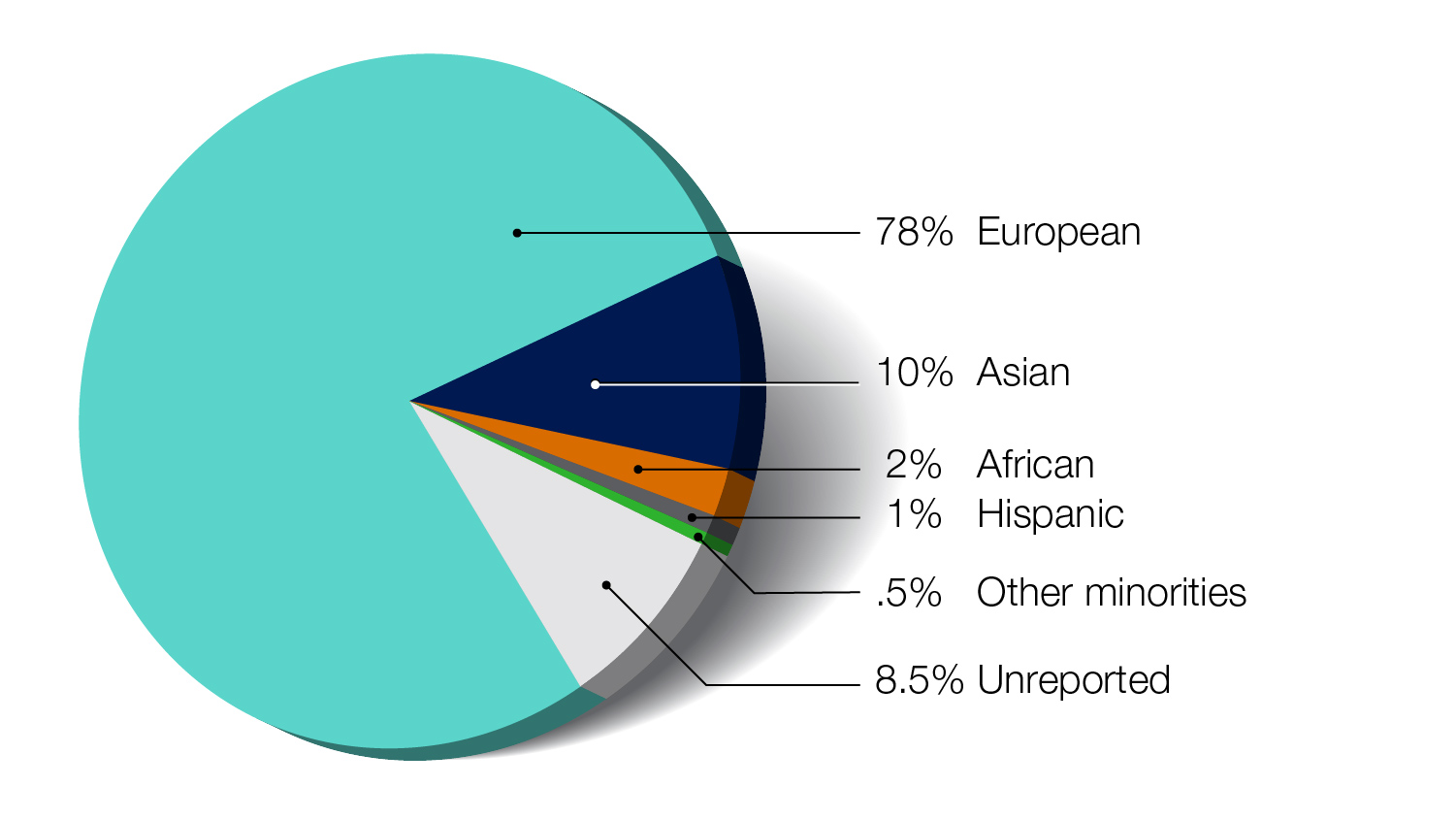
At this point in time, the accuracy of polygenic risk scores may only be valid and useful for European ancestry populations. More research is needed to derive the data for making polygenic risk scores useful for other populations.
Last updated: August 11, 2020