
The Cost of Sequencing a Human Genome
Advances in the field of genomics over the past quarter-century have led to substantial reductions in the cost of genome sequencing. The underlying costs associated with different methods and strategies for sequencing genomes are of great interest because they influence the scope and scale of almost all genomics research projects.
Overview
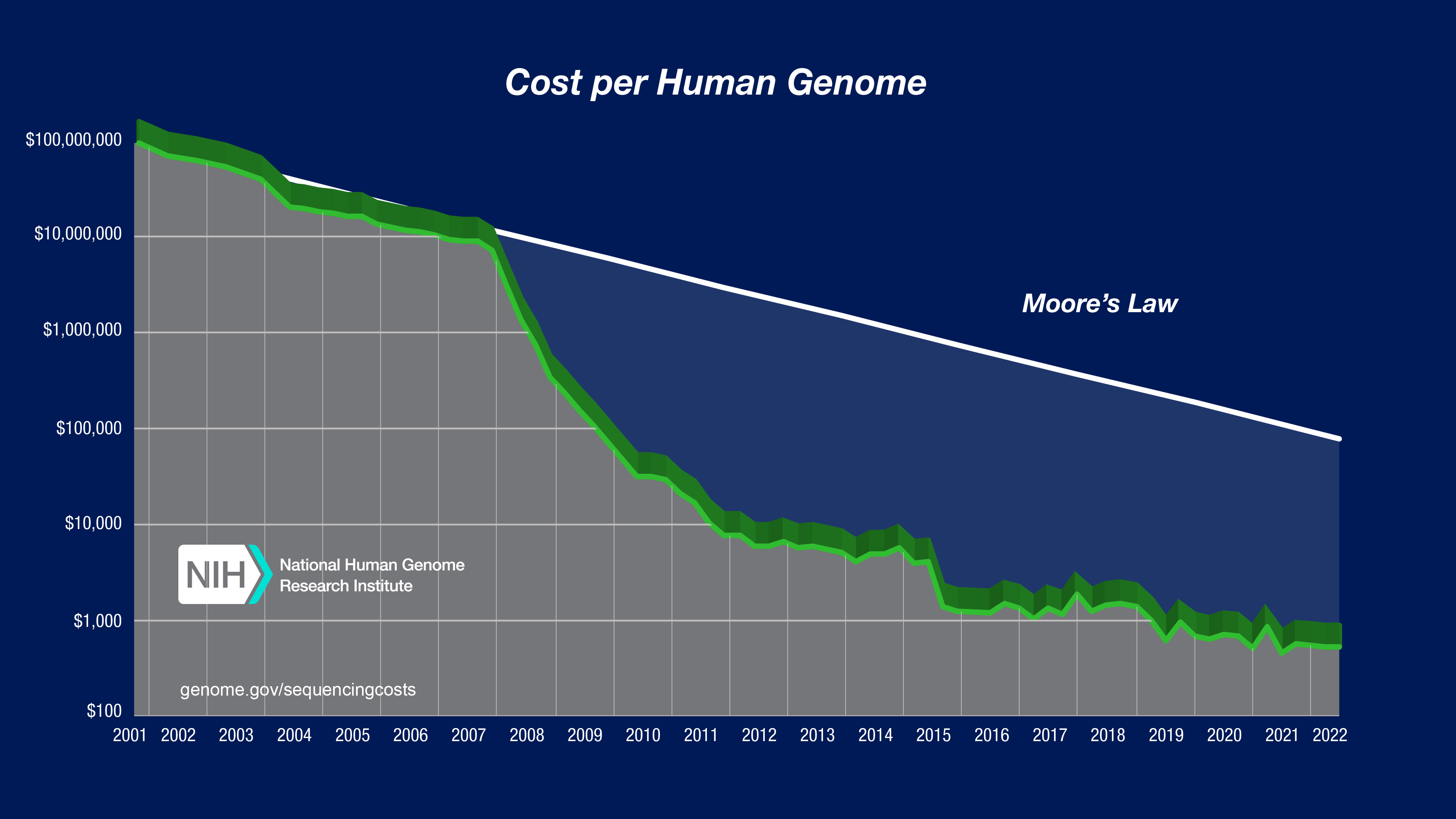
Significant scrutiny and attention have been given to genome-sequencing costs and how they are calculated since the beginning of the field of genomics in the late 1980s. For example, NHGRI has carefully tracked costs per genome at its funded 'genome sequencing centers' for many years (see Figure 1). With the growing scale of human genetics studies and the increasing number of clinical applications for genome sequencing, even greater attention is being paid to understanding the underlying costs of generating a human genome sequence.
Accurately determining the cost for sequencing a given genome (e.g., a human genome) is not simple. There are many parameters to define and nuances to consider. In fact, it is difficult to cite precise genome-sequencing cost figures that mean the same thing to all people because, in reality, different researchers, research institutions, and companies typically track and account for such costs in different fashions.
A Primer on Genome Sequencing
A genome consists of all of the DNA contained in a cell's nucleus. DNA is composed of four chemical building blocks or "bases" (for simplicity, abbreviated G, A, T, and C), with the biological information encoded within DNA determined by the order of those bases. Diploid organisms, like humans and all other mammals, contain duplicate copies of almost all of their DNA (i.e., pairs of chromosomes; with one chromosome of each pair inherited from each parent). The size of an organism's genome is generally considered to be the total number of bases in one representative copy of its nuclear DNA. In the case of diploid organisms (like humans), that corresponds to the sum of the sizes of one copy of each chromosome pair.
Organisms generally differ in their genome sizes. For example, the genome of E. coli (a bacterium that lives in your gut) is ~5 million bases (also called megabases), that of a fruit fly is ~123 million bases, and that of a human is ~3,000 million bases (or ~3 billion bases). There are also some surprising extremes, such as with the loblolly pine tree - its genome is ~23 billion bases in size, over seven times larger than ours. Obviously, the cost to sequence a genome depends on its size. The discussion below is focused on the human genome; keep in mind that a single 'representative' copy of the human genome is ~3 billion bases in size, whereas a given person's actual (diploid) genome is ~6 billion bases in size.
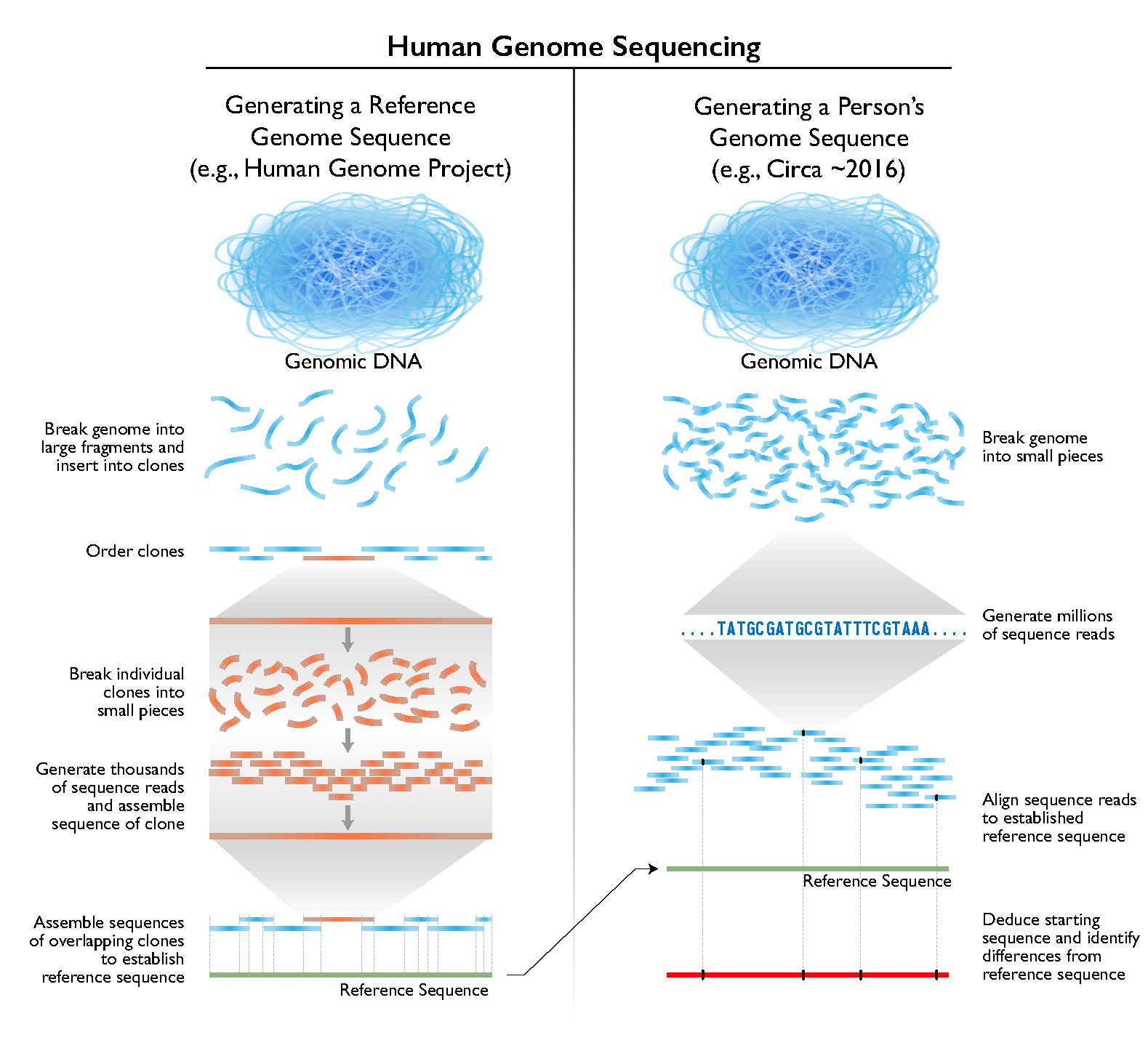
Genomes are large and, at least with today's methods, their bases cannot be 'read out' in order (i.e., sequenced) end-to-end in a single step. Rather, to sequence a genome, its DNA must first be broken down into smaller pieces, with each resulting piece then subjected to chemical reactions that allow the identity and order of its bases to be deduced. The established base order derived from each piece of DNA is often called a 'sequence read,' and the collection of the resulting set of sequence reads (often numbering in the billions) is then computationally assembled back together to deduce the sequence of the starting genome. Sequencing human genomes are nowadays aided by the availability of available 'reference' sequences of the human genome, which play an important role in the computational assembly process. Historically, the process of breaking down genomes, sequencing the individual pieces of DNA, and then reassembling the individual sequence reads to generate a sequence of the starting genome was called 'shotgun sequencing' (although this terminology is used less frequently today). When an entire genome is being sequenced, the process is called 'whole-genome sequencing.' See Figure 2 for a comparison of human genome sequencing methods during the time of the Human Genome Project and circa ~ 2016.
An alternative to whole-genome sequencing is the targeted sequencing of part of a genome. Most often, this involves just sequencing the protein-coding regions of a genome, which reside within DNA segments called 'exons' and reflect the currently 'best understood' part of most genomes. For example, all of the exons in the human genome (the human 'exome') correspond to ~1.5% of the total human genome. Methods are now readily available to experimentally 'capture' (or isolate) just the exons, which can then be sequenced to generate a 'whole-exome sequence' of a genome. Whole-exome sequencing does require extra laboratory manipulations, so a whole-exome sequence does not cost ~1.5% of a whole-genome sequence. But since much less DNA is sequenced, whole-exome sequencing is (at least currently) cheaper than whole-genome sequencing.
Another important driver of the costs associated with generating genome sequences relates to data quality. That quality is heavily dependent upon the average number of times each base in the genome is actually 'read' during the sequencing process. During the Human Genome Project (HGP), the typical levels of quality considered were: (1) 'draft sequence' (covering ~90% of the genome at ~99.9% accuracy); and (2) 'finished sequence' (covering >95% of the genome at ~99.99% accuracy). Producing truly high-quality 'finished' sequence by this definition is very expensive; of note, the process of 'sequence finishing' is very labor-intensive and is thus associated with high costs. In fact, most human genome sequences produced today are 'draft sequences' (sometimes above and sometimes below the accuracy defined above).
There are thus a number of factors to consider when calculating the costs associated with genome sequencing. There are multiple different types and quality levels of genome sequences, and there can be many steps and activities involved in the process itself. Understanding the true cost of a genome sequence therefore requires knowledge about what was and was not included in calculating that cost (e.g., sequence data generation, sequence finishing, upfront activities such as mapping, equipment amortization, overhead, utilities, salaries, data analyses, etc.). In reality, there are often differences in what gets included when estimating genome-sequencing costs in different situations.
Below is summary information about: (1) the estimated cost of sequencing the first human genome as part of the HGP; (2) the estimated cost of sequencing a human genome in 2006 (i.e., roughly a decade ago); and (3) the estimated cost of sequencing a human genome in 2016 (i.e., the present time).
Contact

- Program Operations Lead
- Division of Extramural Operations
Last updated: November 1, 2021